こんにちは。
野中やすおです。
以前の記事で、tabula-pyを使ってpdfのテーブルデータを読み込む内容を紹介しました。
こんにちは。 野中やすおです。 仕事でPythonを使ってpdfをテーブルデータを読み込むことがあり、tabula-pyを活用する機会がありました。 ということもあって今回のtabula-pyというライブラリ使ってPDFフ[…]

今回の記事では、より汎用的にpdfのデータを読み込むことができるpymupdfを紹介します。
pymypdfとは?
pymupdfは、pdf(やその他ドキュメント形式にも対応)ドキュメントのデータ抽出・分析・変換および操作をすることができるPythonライブラリになります。
以下にpymupdfと他のpdfを読み込むライブラリのパフォーマンスを比較した記事があるのですが、pymupdfは一部の実装でCを使っていることもあって、とにかくドキュメントの読み込みが早いという紹介がされています。
PyMuPDF is a high-performance Python library for data extrac…

またEPUBやSVG、画像ファイルにも対応していてドキュメントを操作したい際に選択肢の1つとなるライブラリかなと思います。
pymupdfのインストール方法
pymupdfのインストール方法はpipですることができます。
|
1 |
pip install PyMuPDF |
詳しいバージョン情報については以下のページから参考にしてください。
pymupdfの使い方
今回の記事では、東京都の「令和4年度における決算の状況」を表すpdfファイルを読み込んでいきましょう。
pymupdfの使い方は簡単でまずはfitzをインポートします(pymupdfどこいった?)。ただし、直接ウェブ上のPDFファイルを開くことはできないので、まずはファイルをダウンロードし、ローカルに保存してから読み込む必要があります。なのでrequestsライブラリを使って以下のように書けます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
import fitz import requests # PDFファイルのURL url = 'https://www.zaimu.metro.tokyo.lg.jp/syukei1/zaisei/20231207hutuukaikeikessann.pdf' # requestsを使用してPDFをダウンロード response = requests.get(url) response.raise_for_status() # エラーになった時用 # ローカルにPDFファイルを保存 with open('settlement_reiwa4.pdf', 'wb') as f: f.write(response.content) pdf_document = fitz.open('settlement_reiwa4.pdf', filetype="pdf") pdf_page_1 = pdf_document[0] # テキストを抽出 pdf_text_1 = pdf_page_1.get_text("text") print(pdf_text_1) # 決 算 の 状 況 # 決 # 令 和 4 年 度 # 令 # 和 # 元 # 年 # 度 # ◆ 束 京 都 |
ローカルに保存したpdfファイルをfitz.open で読み込むことができます。今回読み込むファイルはpdfなので、filetypeオプションで”pdf”を指定してあげます。
pdf_document[0]とすると1ページ目のファイルが読み込まれます。そしてget_text(“text”)とするとテキストが抽出されます。その結果を出力しています。
これだけだとつまらないので、より具体的な使い方を次に書きます。
「第1表」という文言をpdf上でみつけて、その下のテーブルをdfとして出力
pdf内に「第1表 令和4年度決算収支」という文言とそれを示すテーブルが存在するので、pdfファイルから文言を検索し、その下のテーブルをDataFrameとして抽出する処理を実行します。ただし、第1表とつくテーブルは複数あるので一番はじめに出てくる文言で抽出します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
import fitz import pandas as pd import requests from pprint import pprint # PDFファイルのURL url = 'https://www.zaimu.metro.tokyo.lg.jp/syukei1/zaisei/20231207hutuukaikeikessann.pdf' # requestsを使用してPDFをダウンロード response = requests.get(url) response.raise_for_status() # ローカルにPDFファイルを保存 with open('settlement_reiwa4.pdf', 'wb') as f: f.write(response.content) pdf_document = fitz.open('settlement_reiwa4.pdf', filetype="pdf") # 指定された文言を探し、該当ページを特定 target_page = None for i in range(len(pdf_document)): page_text = pdf_document[i].get_text("text") if '第1表' in page_text: target_page = pdf_document[i] break # テーブルを検出 if target_page: tables = target_page.find_tables() if tables: table_data = tables[0].extract() pprint(table_data) # 列名を取得 columns = table_data[0] data_rows = table_data[1:] # DataFrameに変換 df = pd.DataFrame(data_rows, columns=columns) print(df) else: print("テーブルが見つかりませんでした。") else: print("指定された文言が見つかりませんでした。") |
出力結果
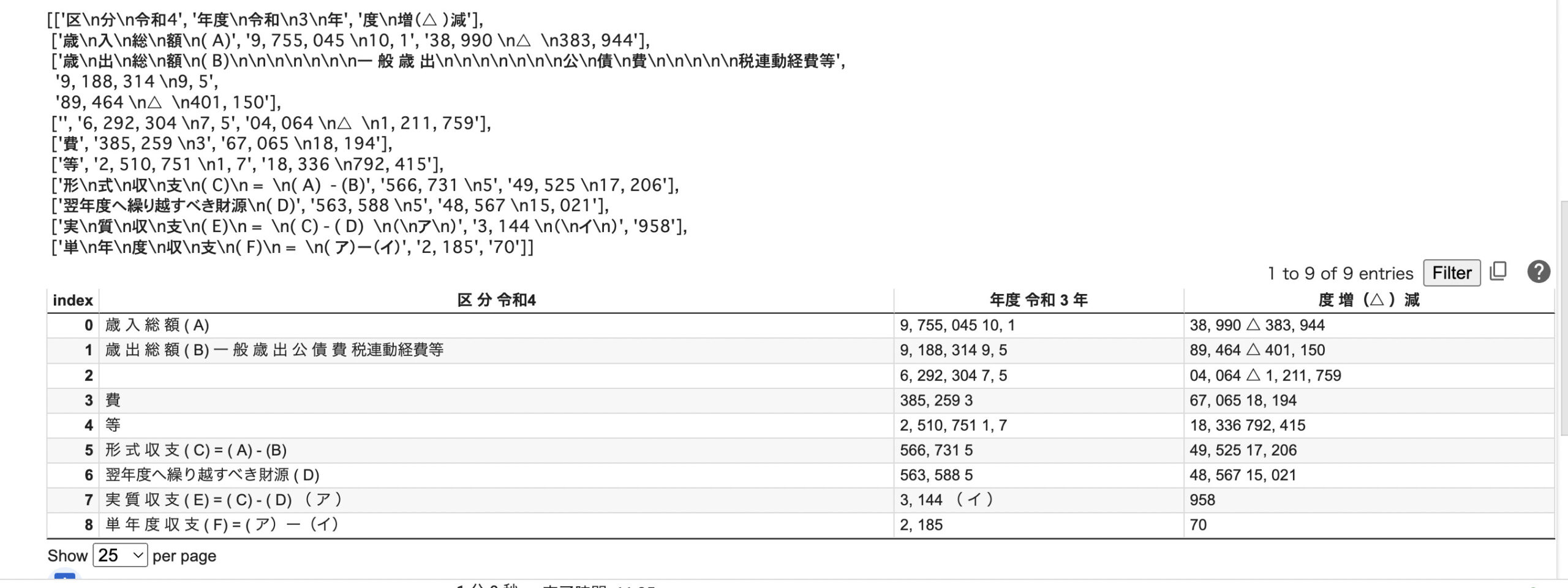
一応、第1表 令和4年度決算収支のテーブルをdfとして取得できました!ただしあまりきれいに抽出してできていないですね(汗)
find_tablesメソッドは、ページ上のテーブルを検索し、テーブルオブジェクトして返します。その後は、extractメソッドを使用して、リストのリストとして返した結果をdfにしています。
もう一つの方法として、テーブルオブジェクトの結果を直接dfで返すto_pandasメソッドもあります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 指定された文言を探し、該当ページを特定 target_page = None for i in range(len(pdf_document)): page_text = pdf_document[i].get_text("text") if '第1表' in page_text: target_page = pdf_document[i] break # テーブルを検出 if target_page: tables = target_page.find_tables() if tables: df = tables[0].to_pandas() print(df) else: print("テーブルが見つかりませんでした。") else: print("指定された文言が見つかりませんでした。") |
出力結果
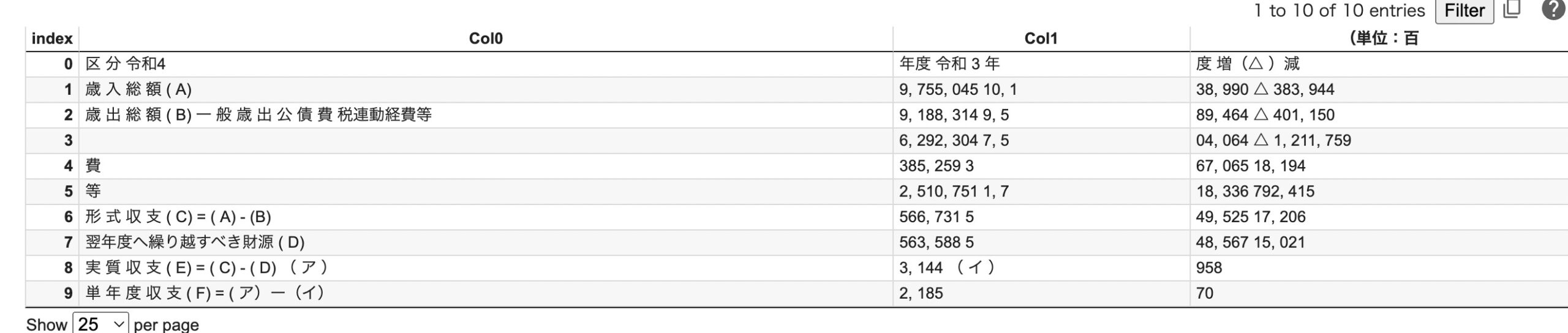
出力結果は特に変わらなさそうなので、dfで返却したい場合は、to_pandasメソッドを利用するのがよさそうです!
そのほかにもfind_tableメソッドにはさまざまなオプションは出力方法があります。
PyMuPDF is a high-performance Python library for data extrac…
実際に業務で活用する際には、ドキュメントを見ながら色々と試行錯誤をしてく必要がありますね。
最後に
以上pymupdfの基本的な使い方を解説しました!
pymupdfはとても柔軟なライブラリで、できることも多く、かつドキュメントも充実しているので私も今後積極的に使っていきたいと思います!

