こんにちは。
野中やすおです。
仕事でPythonを使ってpdfをテーブルデータを読み込むことがあり、tabula-pyを活用する機会がありました。
ということもあって今回のtabula-pyというライブラリ使ってPDFファイルのテーブルデータを読み込む方法を紹介します!
tabula-pyとは
tabula-pyとは、PDFファイル内のテーブルを抽出してPythonのDataFrameに変換するためのライブラリになります。
元々はJavaでつくされていたTabulaというライブラリをPythonで使えるようにしたいものです。
tabula-pyのインストール方法
|
1 |
pip install tabula-py |

また元々TabulaがJavaで開発されていたことからJava runtimeの環境も必要になっています。
必要に応じて、Javaのインストールもしてください。以下のコマンド(Macの場合)でJavaのバージョンの確認とインストールを行なってください。こちらもJava8以上がRequirementsになっています。
|
1 2 3 4 |
java --version openjdk 11.0.19 2023-04-18 OpenJDK Runtime Environment Temurin-11.0.19+7 (build 11.0.19+7) OpenJDK 64-Bit Server VM Temurin-11.0.19+7 (build 11.0.19+7, mixed mode) |
|
1 |
brew install java |
tabula-pyの使用方法
tabula-pyのインストールが完了したら実際に使用していきましょう。
今回のテーブルの作成対象となるデータは、2023年11月にリリースされた「東京都令和6年度予算の要求について」を選びました。
|
1 2 3 4 5 6 |
from tabula import read_pdf budget_request_reiwa6 = 'https://www.zaimu.metro.tokyo.lg.jp/syukei1/zaisei/06yosanyokyujokyou.pdf' dfs = read_pdf(budget_request_reiwa6, pages=1, lattice=True, pandas_options={"dtype": str}) df = dfs[0] |
read_pdfでは、複数のDataFrameが返されるので、そのうちの一番目をdfs[0]と指定することで以下のような結果となります。

上記では、1ページ目の〔各 会 計 要 求 状 況〕 のテーブルが取得されました。
次に第2引数ではpdfのページ全てを指定することもできます。そしてpandas_optionsでは、‘header’: Noneで、ヘッダーを指定しないようにもできます。以下のような実装だと出力はどうなるでしょうか。
|
1 2 3 4 |
budget_request_reiwa6 = 'https://www.zaimu.metro.tokyo.lg.jp/syukei1/zaisei/06yosanyokyujokyou.pdf' dfs = read_pdf(budget_request_reiwa6, pages="all", lattice=True, pandas_options={"dtype": str, 'header': None}) df_2 = dfs[2] |

上記のように1ページ目のテーブル以外の罫線に囲まれた文字列もテーブルとして取得することができました。ちなみにdfs[1]を指定すると「各局からの予算要求の概要については、財務局ホームページにて公表…」の箇所が取得されます。
pagesのオプションでは、1、’all’以外にも‘1-2,3’,や [1,2]など複数ページを指定することもできます。
2ページ目の「局 別 内 訳 ( 一 般 会 計 )」と「会 計 別 総 括 表」も読み込んでみましょう。dfs[3]、dfs[4]で取得できます。
|
1 2 3 4 5 |
budget_request_reiwa6 = 'https://www.zaimu.metro.tokyo.lg.jp/syukei1/zaisei/06yosanyokyujokyou.pdf' dfs = read_pdf(budget_request_reiwa6, pages="all", lattice=True, pandas_options={"dtype": str}) df_3 = dfs[3] df_4 = dfs[4] |

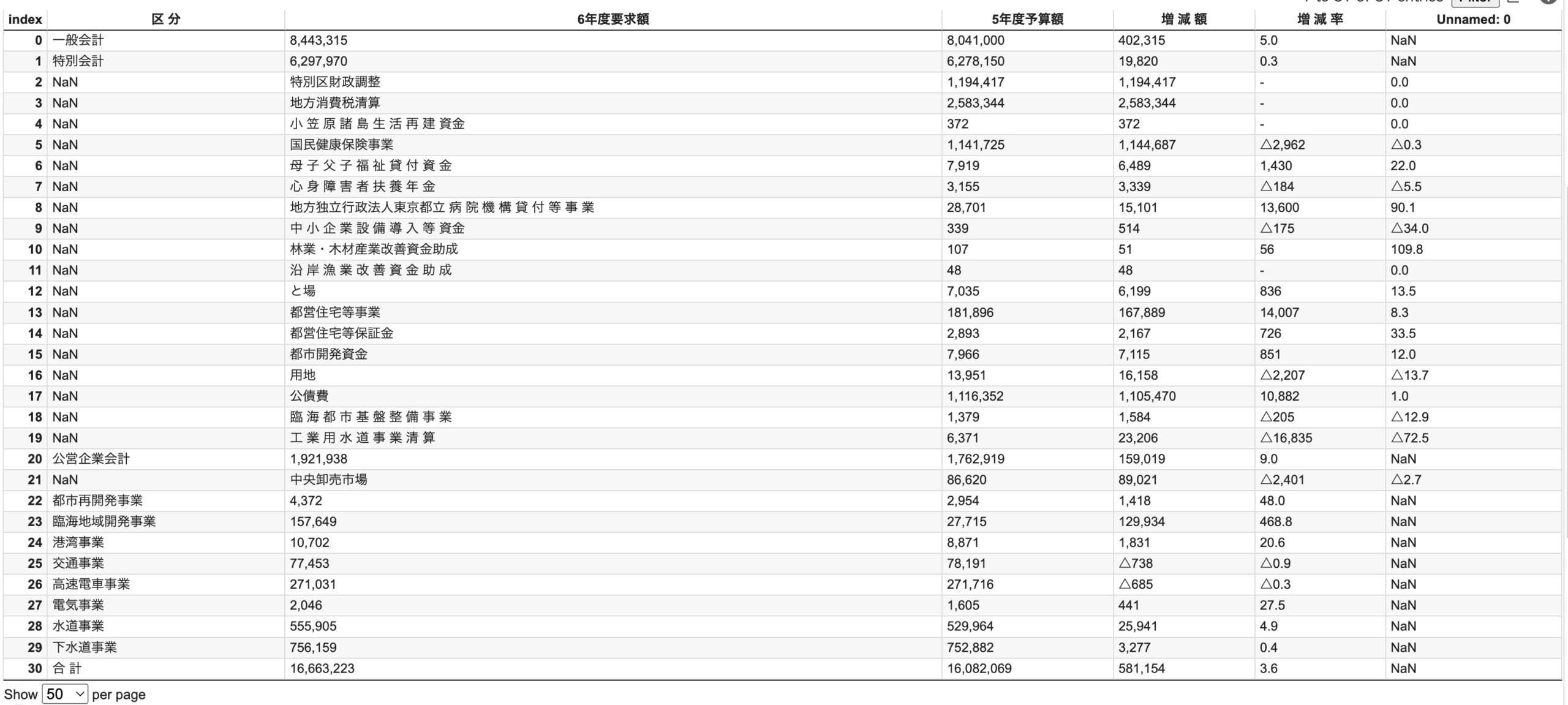
「局 別 内 訳 ( 一 般 会 計 )」は問題なく読み込めましたが、「会 計 別 総 括 表」では区 分列の中でさらに項目が分かれていて、dfの行列がずれてしまいましたね・・・。この場合は、tabula-pyとは別のライブラリの使用を検討する、または行がずれているだけで必要な値は取れているようなのでpdfを読み込んだ後の後処理で対応するといったアプローチがよさそうです。
tabula-pyについて
tabula-pyはあくまでpdf上でテーブル(表)になっているものを読み込むことに主眼を置いているシンプルに使用できるライブラリなので、pdfの文字列を読み込みたい、あるいはテーブルの外側の単位等の文字列も一緒に取得したい場合は他のライブラリとの併用を検討すると良さそうです!
最後に
最後で書くのもなんですが、上記で出力したDataFrameは全て、Google Colab上で動作確認を行い、data_table.enable_dataframe_formatter()を使用することで見栄えを良くしています。dfの見栄えが段違いに良くなるので、こちらもぜひ活用してみてください!
|
1 2 3 4 5 6 7 8 9 10 |
from tabula import read_pdf from google.colab import data_table budget_request_reiwa6 = 'https://www.zaimu.metro.tokyo.lg.jp/syukei1/zaisei/06yosanyokyujokyou.pdf' dfs = read_pdf(budget_request_reiwa6, pages="all", lattice=True, pandas_options={"dtype": str}) df = dfs[0] data_table.enable_dataframe_formatter() print(display(df)) |



